最佳答案
前言
应用程序发生 Crash 现象会给用户带来极差的使用体验,本文将从 iOS 系统的底层出发,梳理核心知识点,讲解各类 Crash 的收集以及 OOM(out
前言
应用程序发生 Crash 现象会给用户带来极差的使用体验,本文将从 iOS 系统的底层出发,梳理核心知识点,讲解各类 Crash 的收集以及 OOM(out of memory) 的监控与分析,以及在 APM 系统中所呈现出来的效果
一、异常处理
1.1 OSX/iOS 系统架构
在苹果给出的文档中,所展示的抽象的系统架构分层图中, OSX 跟 iOS 的系统架构分层是相同,分为4个层次:
- 用户体验层:包括Aqua、Dashboard/Spotlight 等;
- 应用框架层:Cocoa、Carbon、Java;
- 核心框架:有时候也称之为图形和媒体层。包括核心框架、OpenGL;
- Darwin:包括内核和 UNIX shell 环境
4个层次中,Darwin 是完全开源的,是整个系统的基础,提供了底层API。
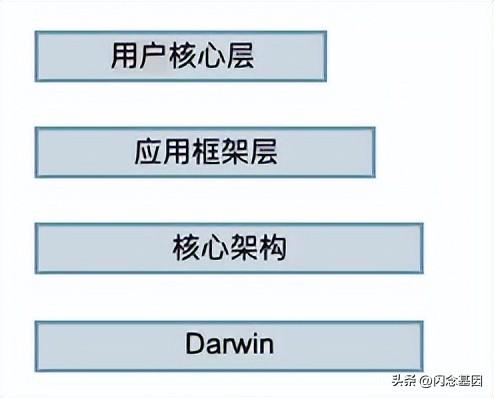
图1 OSX 和 iOS 系统架构图
OSX 跟 iOS 的系统框架在抽象上都是可以用图1表示,但实际上他们之间还是有一些细节上的差异,这里不过多介绍。这里比较重要的是 Darwin 框架
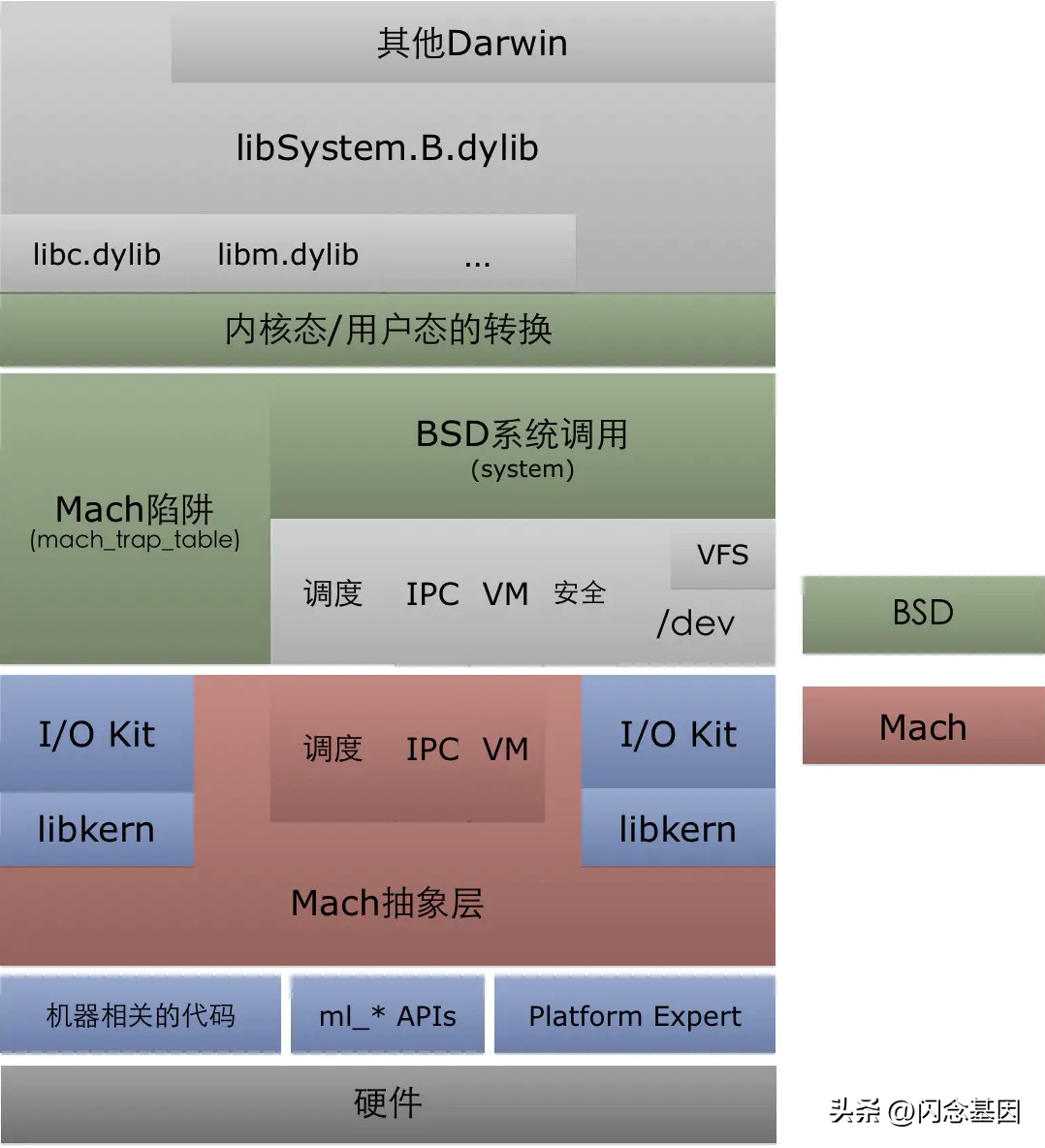
图2 Darwin 框架图 来源《深入解析 Mac OS X & iOS 操作系统》
Darwin 的内核是 XUN,它也是 OS X 本身的核心。从图2可知,XUN以下几种组件构成:
- Mach
- BSD
- LibKern
- I/O Kit
这其中最为重要的是 Mach 跟 BSD。
1.2 Mach层
Mach是一个微内核,这个微内核仅能处理操作系统最基本的职责:
- 进程和线程抽象
- 虚拟内存管理
- 任何调度
- 进程间通信和消息传递机制
Mach 本身的 API 非常有限,但是这些 API 非常基础,如果没有这些 API,其他工作无法实施,而 Mach 的异常处理也是基于以上的4项能力进行设计的。
在Mach中,异常是通过内核中的消息传递,异常由出错的任务或线程通过 msg_send() 抛出,由一个处理程序通过 msg_recv() 捕捉。处理程序可以处理异常,也可以清除异常(将异常标记为已完成并继续),还可以终止线程。
Mach的异常处理程序在不同的上下文运行,出错的线程向预先指定好的异常端口发送消息,然后等待应答。每一个任务都可以注册一个异常端口,这个异常端口会对同一任务中的所有线程起效。此外,单个线程还可以通过 thread_set_exception_ports 注册自己的异常端口。通常情况下,任务和线程的异常端口都是 NULL,也就是说异常不会被处理。而一旦创建异常端口,这些端口就像系统中的其他端口一样,可以转交给其他任务甚至其他主机。
在发生异常时,会按照以下步骤执行:
- 尝试将异常抛给线程中的异常端口
- 尝试抛给任务的异常端口
- 尝试抛给主机的异常端口(即主机注册的默认端口)。
如果没有一个端口返回 KERN_SUCCESS,那么整个任务被终止,根据前文的叙述,Mach 不提供异常处理逻辑——只是提供异常通知的框架。
1.3 BSD层
BSD 层建立在Mach之上,这一层是一个很可靠且更现代的 API,提供了 POSIX 兼容性,并提供了更高层次的抽象,包括但不限于:
- UNIX 进程模型
- POSiX 线程模型(pthread)以及相关的同步原语
- UNIX 用户和组
- 网络协议栈
- 文件系统访问
- 设备访问
在处理异常上,Mach 已经通过异常机制提供了底层的陷阱处理,而 BSD 则在异常机制之上,构建了一个信号处理机制。硬件产生的信号被 Mach 层捕捉,然后转换为对应的 UNIX 信号。为了维护一个统一的机制,操作系统和用户产生的信号首先被转换为 Mach 异常,然后再转换为信号。
BSD 进程被 bsdinit_task() 函数启动时,还调用了 ux_handle_init() 函数,这个函数设置了一个名为ux_handle 的 Mach 内核线程。只有在 ux_handle_init() 函数返回之后,bsdinit_task() 才能够注册使用ux_exception_port。bsdinit_task() 将所有的Mach异常消息都重定向到ux_exception_port,这个端口由 ux_handle 线程持有。遵循 Mach 异常消息传递的方式,PID 为1的进程异常处理会在进程之外由 ux_handle() 线程处理。由于所有后创建的用户态进程都是 PID1 的后代,所以这些进程会自动继承这个异常端口,相当于 ux_handle() 线程要负责处理系统上 UNIX 进程产生的每一个Mach异常。ux_handle() 函数非常简单,这个函数在进入时会首先设置好 ux_handle_port,然后进入一个无限循环的 Mach 消息循环。消息循环接受 Mach 异常消息,然后调用mach_exc_server() 处理异常,整个流程图如下所示:
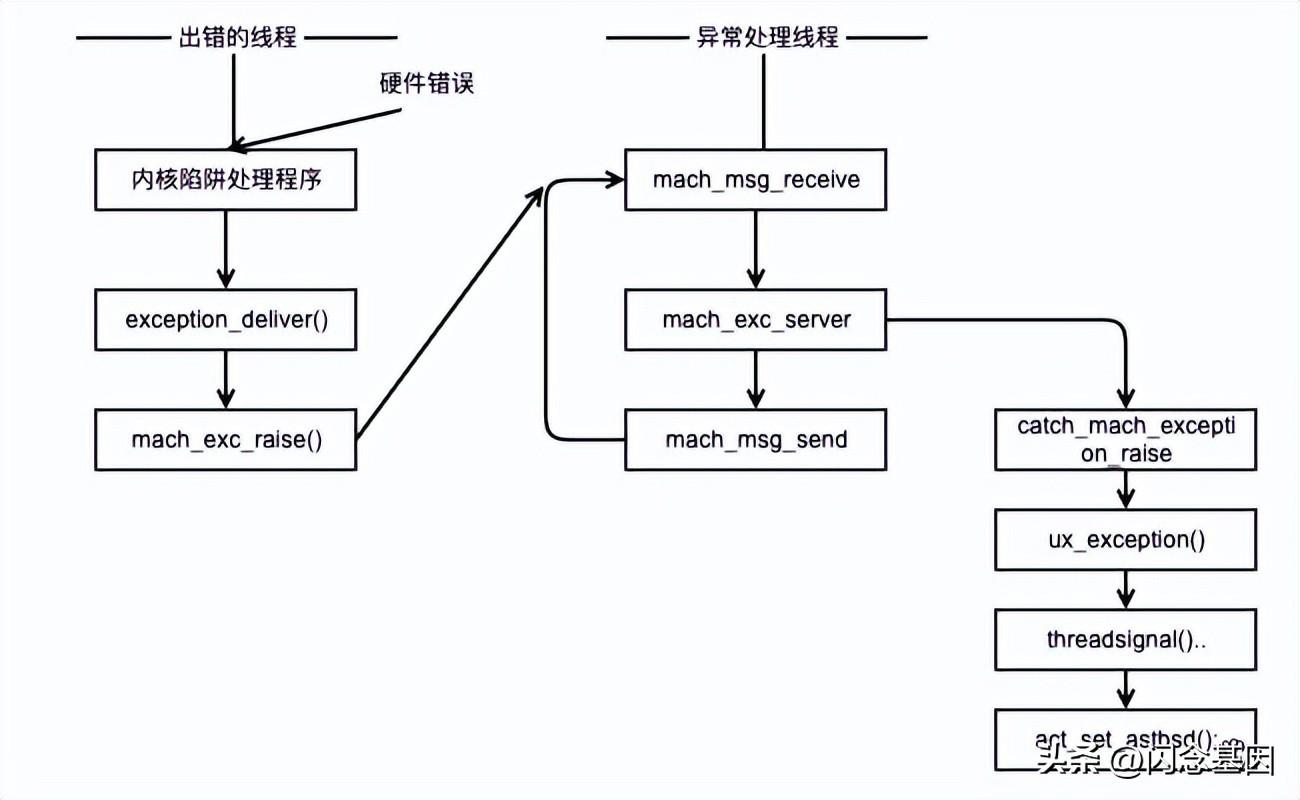
图3 Mach 异常处理以及转换为 UNIX 信号的流程
二、Crash收集方式
要了解 Crash,我们应该先清楚几个基本概念以及它们之间的关系:
- 软件异常:主要来源于两个API的调用kill()、pthread_kill(),而 iOS 中常遇到的 NSException 未捕获、abort()函数调用都属于这种情况。
- 硬件异常:此类异常始于处理器陷阱,如访问野指针崩溃。
- Mach异常:Mach 异常处理流程的简称
- UNIX信号: 如 SIGBUS 、 SIGSEGV 、 SIGABRT 、 SIGKILL 等。
|
...... Exception Type: EXC_CRASH (SIGABRT) Exception Codes: 0x0000000000000000, 0x0000000000000000 Exception Note: EXC_CORPSE_NOTIFY Triggered by Thread: 0 Last Exception Backtrace: 0 CoreFoundation 0x1843765ac __exceptionPreprocess + 220 (NSException.m:199) 1 libobjc.A.dylib 0x1983f042c objc_exception_throw + 60 (objc-exception.mm:565) ...... |
这是一个 App 的崩溃日志,从日志中的 Exception Type: EXC_CRASH (SIGABRT) 可以知道这是 Mach 层发生了EXC_CRASH异常,被转换 SIGABRT 信号。那么你可能有一个疑问?既然 Mach 层可以捕获异常,注册 UNIX 信号也能捕获异常,那么这两种方法系统是如何选择?而且从图3中可以看出 Mach 异常最终都会转换成 UNIX 信号,那么是不是只需要拦截 UNIX 信号就可以了?
其实不是的,这里面有两个原因:
- 因为并不是所有的 Mach 异常类型都有相对应的 UNIX 信号进行映射
- UNIX 信号在崩溃线程回调,如果遇到栈溢出,那么就没有栈空间可以执行回调代码了。
那么是否只需要拦截 Mach 异常?答案一样是否定的,因为用户态的软件异常是直接走信号流程的,如果不拦截,会导致这部分 Crash 丢失。
因此,在 Crash 的收集上,监控系统应该具备多种异常处理能力的,市面上有许多诸如此类的工具,其中一款有 KSCrash,该工具也是目前最热门,最完善的 Crash 收集工具,大部分源码基于C语言编写,微信的开源项目 Matrix 也是基于 KSCrash 开发,而我们的 APM 系统中的 iOS 崩溃监控也是基于该工具上进行编写的。
2.1 Mach 层异常处理
读源码是了解工具最快的方式,让我们看一下 KSCrash 是如何处理Mach层异常的核心源码(KSCrashMonitor_MachException.c)如下:
|
static bool installExceptionHandler() { ...... //获取当前task const task_t thisTask = mach_task_self(); exception_mask_t mask = EXC_MASK_BAD_ACCESS | EXC_MASK_BAD_INSTRUCTION | EXC_MASK_ARITHMETIC | EXC_MASK_SOFTWARE | EXC_MASK_BREAKPOINT; //获取当前task所有的异常端口并保存在kr属性中 kr = task_get_exception_ports(thisTask, mask, g_previousExceptionPorts.masks, &g_previousExceptionPorts.count, g_previousExceptionPorts.ports, g_previousExceptionPorts.behaviors, g_previousExceptionPorts.flavors); if (kr != KERN_SUCCESS) { KSLOG_ERROR("task_get_exception_ports: %s", mach_error_string(kr)); goto failed; } if (g_exceptionPort == MACH_PORT_NULL) { KSLOG_DEBUG("Allocating new port with receive rights."); //申请一个异常端口 kr = mach_port_allocate(thisTask, MACH_PORT_RIGHT_RECEIVE, &g_exceptionPort); if (kr != KERN_SUCCESS) { KSLOG_ERROR("mach_port_allocate: %s", mach_error_string(kr)); goto failed; } KSLOG_DEBUG("Adding send rights to port."); //设置端口权限 kr = mach_port_insert_right(thisTask, g_exceptionPort, g_exceptionPort, MACH_MSG_TYPE_MAKE_SEND); if (kr != KERN_SUCCESS) { KSLOG_ERROR("mach_port_insert_right: %s", mach_error_string(kr)); goto failed; } } ...... //创建对应的线程,捕获异常 error = pthread_create(&g_secondaryPThread, &attr, &handleExceptions, kThreadSecondary); ...... |
根据源码可以总结出以下的流程图:
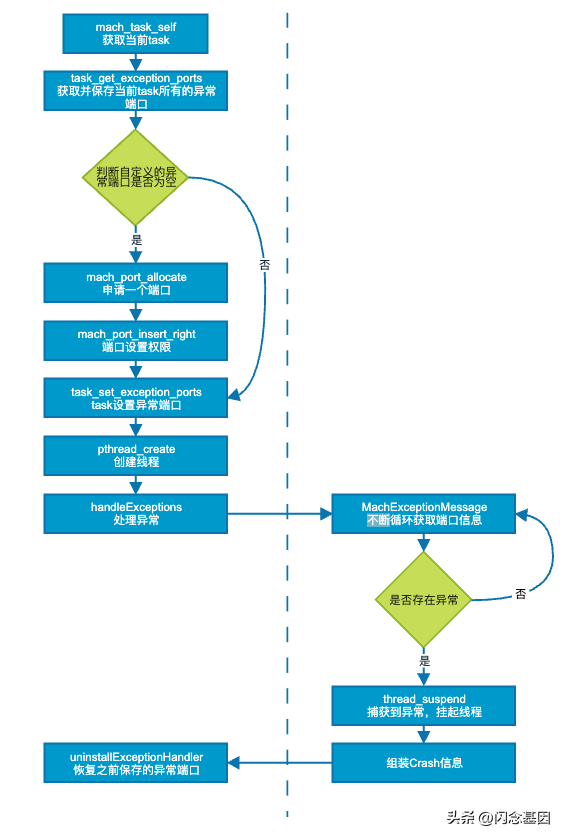
在1.2中,提到过 Mach 层对异常的处理流程,因此在 Mach 层的异常捕获也是根据这一处理流程进行的,思路是先申请一个异常处理端口,为该端口申请权限,再设置异常端口,新建一个内核线程,在线程中循环等待异常,但发生异常时,会挂起线程并组装发生 Crash 时的信息进 JSON 文件。但为了防止自己注册的异常端口抢占其他 SDK、或者开发者设置的逻辑,需要先保存其他异常端口,等到收集逻辑结束后将异常处理交给其他端口内的逻辑处理。
2.2 信号异常处理
信号异常的捕获是在 KSCrashMonitor_signal.c 中的 installSignalHandler 函数中,具体的方案为首先先使用 sigaltstack 函数在堆上分配一块内存,设置信号栈区域,目的是替换信号处理函数的栈,因为一个进程可能有n个线程,每个线程都有自己的任务,假如某个线程执行出错,会导致整个进程奔溃,所以为了信号处理异常函数正常运行,需要设置单独的运行空间。
其次设置信号处理函数 sigaction,然后遍历需要处理的信号数组,将每个信号的处理函数绑定到 sigaction,另外用 g_previousSignalHandlers 保存当前信号的处理函数,在信号处理时,保存线程的上下文信息。
最后等到 KSCrash 信号处理后还原之前的信号处理权限。
核心代码如下:
|
static bool installSignalHandler() { KSLOG_DEBUG("Installing signal handler."); # if KSCRASH_HAS_SIGNAL_STACK // 在堆上分配一块内存, if (g_signalStack.ss_size == 0) { KSLOG_DEBUG("Allocating signal stack area."); g_signalStack.ss_size = SIGSTKSZ; g_signalStack.ss_sp = malloc(g_signalStack.ss_size); } KSLOG_DEBUG("Setting signal stack area."); // 信号处理函数的栈挪到堆中,不和进程共用一块栈区 if (sigaltstack(&g_signalStack, NULL) != 0) { KSLOG_ERROR("signalstack: %s", strerror(errno)); goto failed; } #endif const int * fatalSignals = kssignal_fatalSignals(); int fatalSignalsCount = kssignal_numFatalSignals(); if (g_previousSignalHandlers == NULL) { KSLOG_DEBUG("Allocating memory to store previous signal handlers."); g_previousSignalHandlers = malloc(sizeof(*g_previousSignalHandlers) * (unsigned)fatalSignalsCount); } // 设置信号处理函数 sigaction 的第二个参数,类型为 sigaction 结构体 struct sigaction action = {{0}}; action.sa_flags = SA_SIGINFO | SA_ONSTACK; # if KSCRASH_HOST_APPLE && defined(__LP64__) action.sa_flags |= SA_64REGSET; #endif sigemptyset(&action.sa_mask); action.sa_sigaction = &handleSignal for ( int i = 0; i < fatalSignalsCount; i++) { KSLOG_DEBUG("Assigning handler for signal %d", fatalSignals[i]); // 将每个信号的处理函数绑定到上面声明的 action 去,另外用 g_previousSignalHandlers 保存当前信号的处理函数 if (sigaction(fatalSignals[i], &action, &g_previousSignalHandlers[i]) != 0) { char sigNameBuff[30]; const char * sigName = kssignal_signalName(fatalSignals[i]); if (sigName == NULL) { snprintf(sigNameBuff, sizeof(sigNameBuff), "%d", fatalSignals[i]); sigName = sigNameBuff; } KSLOG_ERROR("sigaction (%s): %s", sigName, strerror(errno)); // Try to reverse the damage for (i--;i >= 0; i--) { sigaction(fatalSignals[i], &g_previousSignalHandlers[i], NULL); } goto failed; } } KSLOG_DEBUG("Signal handlers installed."); return true ; failed: KSLOG_DEBUG("Failed to install signal handlers."); return false ; } ...... |
2.3 C++异常处理
c++异常处理依靠了标准库的 std::set_terminate(CPPExceptionTerminate) 函数。
在iOS中,如果C跟C++异常如果能被转换成NSException,则会走Objective-C异常处理,如果不能,则是default_terminate_handler。这个C++异常默认default_terminate_handler函数调用了abort_message函数,系统产生一个SIGABRT信号。
|
static void CPPExceptionTerminate( void ) { ...... // 之前判断是否是cpp exception的条件,继承自NSException的NSException会被当做cpp exception处理 // if (name == NULL || strcmp(name, "NSException") != 0 if (g_capturedStackCursor && (name == NULL || strcmp(name, "NSException") != 0)) { kscm_notifyFatalExceptionCaptured( false ); KSCrash_MonitorContext* crashContext = &g_monitorContext; memset(crashContext, 0, sizeof(*crashContext)); char descriptionBuff[DESCRIPTION_BUFFER_LENGTH]; const char * description = descriptionBuff; descriptionBuff[0] = 0; KSLOG_DEBUG("Discovering what kind of exception was thrown."); g_captureNextStackTrace = false ; try { throw ; } catch (std::exception& exc) { strncpy(descriptionBuff, exc.what(), sizeof(descriptionBuff)); } ...... |
2.4 Objective-C 异常处理
对于 OC 层面的 NSException 异常处理较为容易,可以通过注册 NSUncaughtExceptionHandler 来捕获异常信息,通过 NSException 参数来做 Crash 信息的收集,交给数据上报组件。如
KSCrash.sharedInstance.uncaughtExceptionHandler = &handleException
三、OOM 相关概念
OOM 就是 out of memory 的简称,指的是在 iOS 设备上当前应用因为内存占用过高而被操作系统强制终止,在用户侧的感知就是 App 一瞬间的闪退,与普通的 Crash 没有明显差异。但是当我们在调试阶段遇到这种崩溃的时候,在设备中分析与改进是找不到普通的崩溃日志。可以找到以Jetsam开头的日志,这种日志 就是 OOM 崩溃之后系统生成的一种专门反映内存异常问题的日志。
按照程序的运行状态一般把OOM分为以下两种类型:
- Foreground Out Of Memory
应用正在前台运行的状态而出现OOM崩溃
- Background Out Of Memory
应用程序在后台发生的 OOM 崩溃
Jetsam
Jetsam 是 iOS 操作系统为了控制内存资源过度使用而采用的一种资源管理机制。不同于 MacOS, Linux,Windows等桌面操作系统,出于性能方面的考虑,iOS 系统并没有设计内存交换空间的机制,所以在 iOS 中,如果设备整体内存紧张的话,系统只能将一些优先级不高或占用内存过大的进程直接终止掉。
下面截取的部分日志信息:
|
{ "uuid" : "a02fb850-9725-4051-817a-8a5dc0950872", "states" : [ "frontmost" //应用状态:前台运行 ], "lifetimeMax" : 92802, "purgeable" : 0, "coalition" : 68, "rpages" : 92802, //占用内存页 "reason" : "per-process-limit", //崩溃原因:超过单进程上限 "name" : "MyCoolApp" } |
详细说明可以参考 官方文档
Jetsam机制清理策略分为两种情况:
- 单个 App 进程超过内存上线
-
设备的物理内存占用受到压力时会按照优先级完成清理:
- 后台应用 > 前台应用
- 内存占用高的应用 > 内存占用低的应用
- 用户应用 > 系统应用
功能介绍&原理
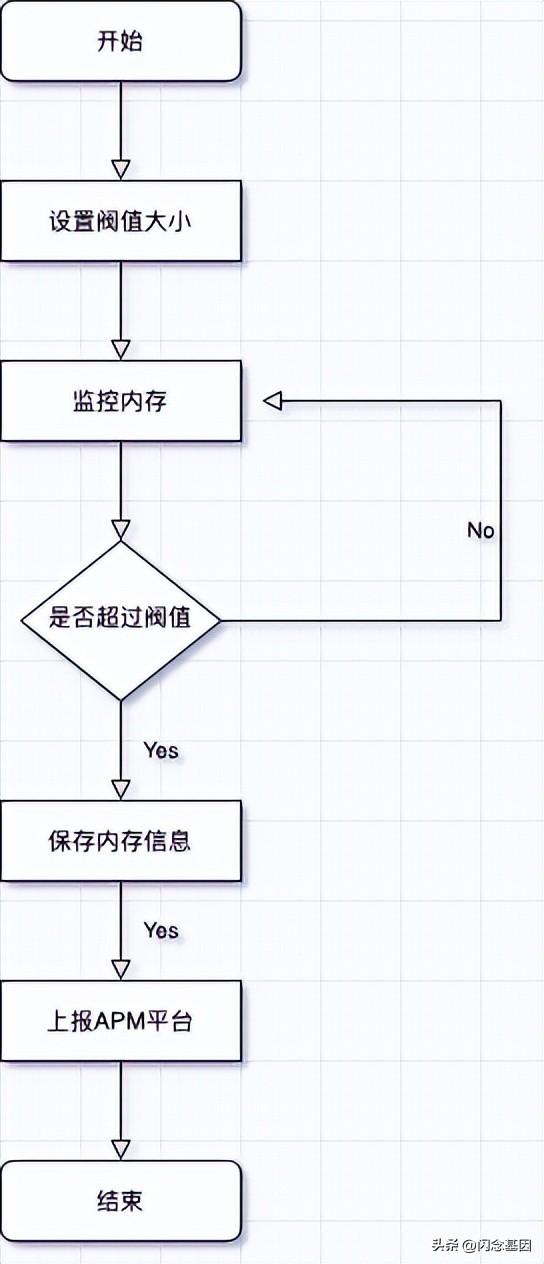
OOM预警
OOM预警功能主要是在内存到达预定的阀值时,上报APM平台内存状态相关信息。流程图如下:
基于系统内核提供一个表示内存信息的结构体
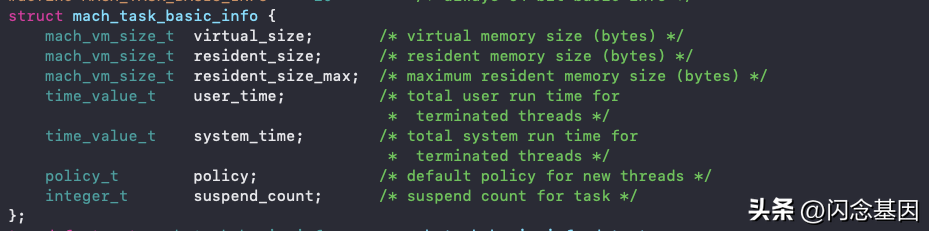
通过 task_info 方法 可以获得内存的相关使用情况
|
kern_return_t task_info ( task_name_t target_task, task_flavor_t flavor, task_info_t task_info_out, mach_msg_type_number_t *task_info_outCnt ); |
监控内存大小代码如下:
|
int64_t memoryUsageInByte = 0; task_vm_info_data_t vmInfo; mach_msg_type_number_t count = TASK_VM_INFO_COUNT; kern_return_t kernelReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count); if (kernelReturn == KERN_SUCCESS) { memoryUsageInByte = (int64_t) vmInfo.phys_footprint; } |
触顶处理逻辑如下:
即当超过设定的阀值时,就上报当时的内存信息!
|
-( void )saveLastSingleLoginMaxMemory{ if (_hasUpoad){ NSString* currentMemory = [NSString stringWithFormat:@"%f", _singleLoginMaxMemory]; NSString* overflowMemoryLimit =[NSString stringWithFormat:@"%f", overflow_limit]; if (_singleLoginMaxMemory > overflow_limit){ static BOOL isFirst = YES; if (isFirst){ _firstOOMTime = [[NSDate date] timeIntervalSince1970]; isFirst = NO; } } NSDictionary *minidumpdata = [NSDictionary dictionaryWithObjectsAndKeys:currentMemory,@"singleMemory",overflowMemoryLimit,@"threshold",[NSString stringWithFormat: @"%.2lf", _firstOOMTime],@"LaunchTime",nil]; NSString *fileDir = [self singleLoginMaxMemoryDir]; if (![[NSFileManager defaultManager] fileExistsAtPath:fileDir]) { [[NSFileManager defaultManager] createDirectoryAtPath:fileDir withIntermediateDirectories:YES attributes:nil error:nil]; } NSString *filePath = [fileDir stringByAppendingString:@"/apmLastMaxMemory.plist"]; if (minidumpdata != nil){ if ([[NSFileManager defaultManager] fileExistsAtPath:filePath]){ [[NSFileManager defaultManager] removeItemAtPath:filePath error:nil]; } [minidumpdata writeToFile:filePath atomically:YES]; } } } |
模拟内存触顶得到日志记录:
OOM监控
OOM监控是在App由于OOM导致的崩溃时,及时记录当时的堆栈信息,上报到APM平台进行后续的问题分析。
Jetsam机制终止进程的时候是通过发送SIKILL异常信号,但它是不可以被当前进程捕获,用监听异常信号常规的Crash捕获方案是不行的。那如何监控呢?2015年facebook提出一个思路,利用排除法。
每次App 启动的时候判断上一次启动进程终止的原因,已知的有:
- App 更新了版本
- App 发生了崩溃
- 用户手动退出
- 操作系统更新了版本
- App 切换后台之后进程终止
如果上一次的启动进程终止不是以上的原因,就判定为上次启动发生了 OOM 崩溃。
核心代码逻辑如下:
|
-(NSDictionary *)parseFoomData:(NSDictionary *)foomDict { ...... if (appState == APPENTERFORGROUND){ BOOL isExit = [[foomDict objectForKey:@"isExit"] boolValue]; BOOL isDeadLock = [[foomDict objectForKey:@"isDeadLock"] boolValue]; NSString *lastSysVersion = [foomDict objectForKey:@"systemVersion"]; NSString *lastAppVersion = [foomDict objectForKey:@"appVersion"]; if (!isCrashed && !isExit && [_systemVersion isEqualToString:lastSysVersion] && [_appVersion isEqualToString:lastAppVersion]){ if (isDeadLock){ OOM_Log("The app ocurred deadlock lastTime,detail info:%s",[[foomDict description] UTF8String]); [result setObject:@deadlock_crash forKey:@"crash_type"]; NSDictionary *stack = [foomDict objectForKey:@"deadlockStack"]; if (stack && stack.count > 0){ [result setObject:stack forKey:@"stack_deadlock"]; OOM_Log("The app deadlock stack:%s",[[stack description] UTF8String]); } } else { OOM_Log("The app ocurred foom lastTime,detail info:%s",[[foomDict description] UTF8String]); [result setObject:@foom_crash forKey:@"crash_type"]; NSString * uuid = [foomDict objectForKey:@"uuid"]; NSArray *oomStack = [[OOMDetector getInstance] getOOMDataByUUID: uuid ]; if (oomStack && oomStack.count > 0) { NSData *oomData = [NSJSONSerialization dataWithJSONObject:oomStack options:0 error:nil]; if (oomData.length > 0){ // NSString *stackStr = [NSString stringWithUTF8String:(const char *)oomData.bytes]; OOM_Log("The app foom stack:%s",[[oomStack description] UTF8String]); } [result setObject:[self getAPMOOMStack:oomStack] forKey:@"stack_oom"]; } } return result; } } ...... } |
内存画像
内存画像,就是程序在达到触顶情况时,对内存进行快照,导出内存节点引用情况,从而找到内存大的原因在哪!要做的事情有两个:
1.内存节点的获取
内存节点的获取要通过mach内核的vm_region_recurse/vm_region_recure64函数扫描进程中的所有VM Region,通过vm_region_submap_info_64结构体获取详细信息。
2.分析节点之间的引用关系
这里又分为两种情况:libmalloc维护的堆所在的VM Region包含的OC对象、C/C++对象、buffer等可以获取详细的引用关系,需要单独处理。而非libmalloc维护的VM Region单独的内存节点,仅记录了起始地址和Dirty、Swapped内存大小,以及与其他节点之间的引用关系。
获取节点的核心代码如下:
|
void VMRegionCollect::startCollet() { ...... while (1) { struct vm_region_submap_info_64 info; mach_msg_type_number_t count = VM_REGION_SUBMAP_INFO_COUNT_64; krc = vm_region_recurse_64(mach_task_self(), &address, &size, &depth, (vm_region_info_64_t)&info, &count); if (krc == KERN_INVALID_ADDRESS){ break ; } if (info.is_submap){ depth++; } else { //do stuff proc_regionfilename(pid, address, buf, sizeof (buf)); printf ("Found VM Region: %08x to %08x (depth=%d) user_tag:%s name:%s\n", (uint32_t)address, (uint32_t)(address+size), depth, [visualMemoryTypeString(info.user_tag) cStringUsingEncoding:NSUTF8StringEncoding], buf); address += size; } } } |
扫描节点 case 数据信息如下:

堆内存节点引用关系的核心代码如下:
通过类成员变量的地址与引用类的isa指针地址进行匹配,从而发现是否存在引用关系!
|
static void range_callback(task_t task, void *context, unsigned type, vm_range_t *ranges, unsigned rangeCount) { if (!context) { return ; } for (unsigned int i = 0; i < rangeCount; i++) { vm_range_t range = ranges[i]; flex_maybe_object_t *tryObject = (flex_maybe_object_t *)range.address; Class tryClass = NULL; #ifdef __arm64__ // See http://www.sealiesoftware.com/blog/archive/2013/09/24/objc_explain_Non-pointer_isa.html extern uint64_t objc_debug_isa_class_mask WEAK_IMPORT_ATTRIBUTE; tryClass = (__bridge Class)(( void *)((uint64_t)tryObject->isa & objc_debug_isa_class_mask)); #else tryClass = tryObject->isa; #endif // If the class pointer matches one in our set of class pointers from the runtime, then we should have an object. if (CFSetContainsValue(registeredClasses, (__bridge const void *)(tryClass))) { (*(object_enumeration_block_t __unsafe_unretained *)context)((__bridge id)tryObject, tryClass); } } } static kern_return_t reader(__unused task_t remote_task, vm_address_t remote_address, __unused vm_size_t size, void **local_memory) { *local_memory = ( void *)remote_address; return KERN_SUCCESS; } + ( void )enumerateLiveObjectsUsingBlock:(object_enumeration_block_t)block { if (!block) { return ; } [self updateRegisteredClasses]; vm_address_t *zones = NULL; unsigned int zoneCount = 0; kern_return_t result = malloc_get_all_zones(TASK_NULL, reader, &zones, &zoneCount); if (result == KERN_SUCCESS) { for (unsigned int i = 0; i < zoneCount; i++) { malloc_zone_t *zone = (malloc_zone_t *)zones[i]; malloc_introspection_t *introspection = zone->introspect; if (!introspection) { continue ; } void (*lock_zone)(malloc_zone_t *zone) = introspection->force_lock; void (*unlock_zone)(malloc_zone_t *zone) = introspection->force_unlock; object_enumeration_block_t callback = ^(__unsafe_unretained id object, __unsafe_unretained Class actualClass) { unlock_zone(zone); block(object, actualClass); lock_zone(zone); }; BOOL lockZoneValid = PointerIsReadable(lock_zone); BOOL unlockZoneValid = PointerIsReadable(unlock_zone); if (introspection->enumerator && lockZoneValid && unlockZoneValid) { lock_zone(zone); introspection->enumerator(TASK_NULL, ( void *)&callback, MALLOC_PTR_IN_USE_RANGE_TYPE, (vm_address_t)zone, reader, ⦥_callback); unlock_zone(zone); } } } } |
获取引用关系的 case 数据如下:
采用了倒序输出引用关系,所以看上去是阶梯型形式!
取出其中部分数据借用工具分析其引用关系如图:
这样可以很清晰的看到其堆内存节点间的引用关系及所占内存大小。
总结
以上便是APM系统中关于 OOM 的功能的介绍,主要包含三大功能点:
- OOM 预警可以发现线上App发生超过内存阀值时记录,以标识存在 OOM 导致 crash 的风险。
- OOM 监控则在发生 OOM 时及时记录案发现场,给后续开发者问题查找提供线索。
- 内存画像则在发生OOM 时导出其引用关系,记录节点大小等信息,更直观的查找内存大在何处。
四、Crash日志
4.1 APM上报Crash日志流程
项目集成 APM,SDK 初始化时,会默认打开 Crash 监控,当发生 Crash 时,将按照以下步骤执行:
- KSCrash 收集到崩溃日志后执行 APM 的 crashCallBack函数
- 在 crashCallBack 函数中将日志写入 APMLog 并缓存起来
- 当下次启动时,APM 初始化成功后按照上报流程上报Crash 文件到服务器中
4.2 日志解析
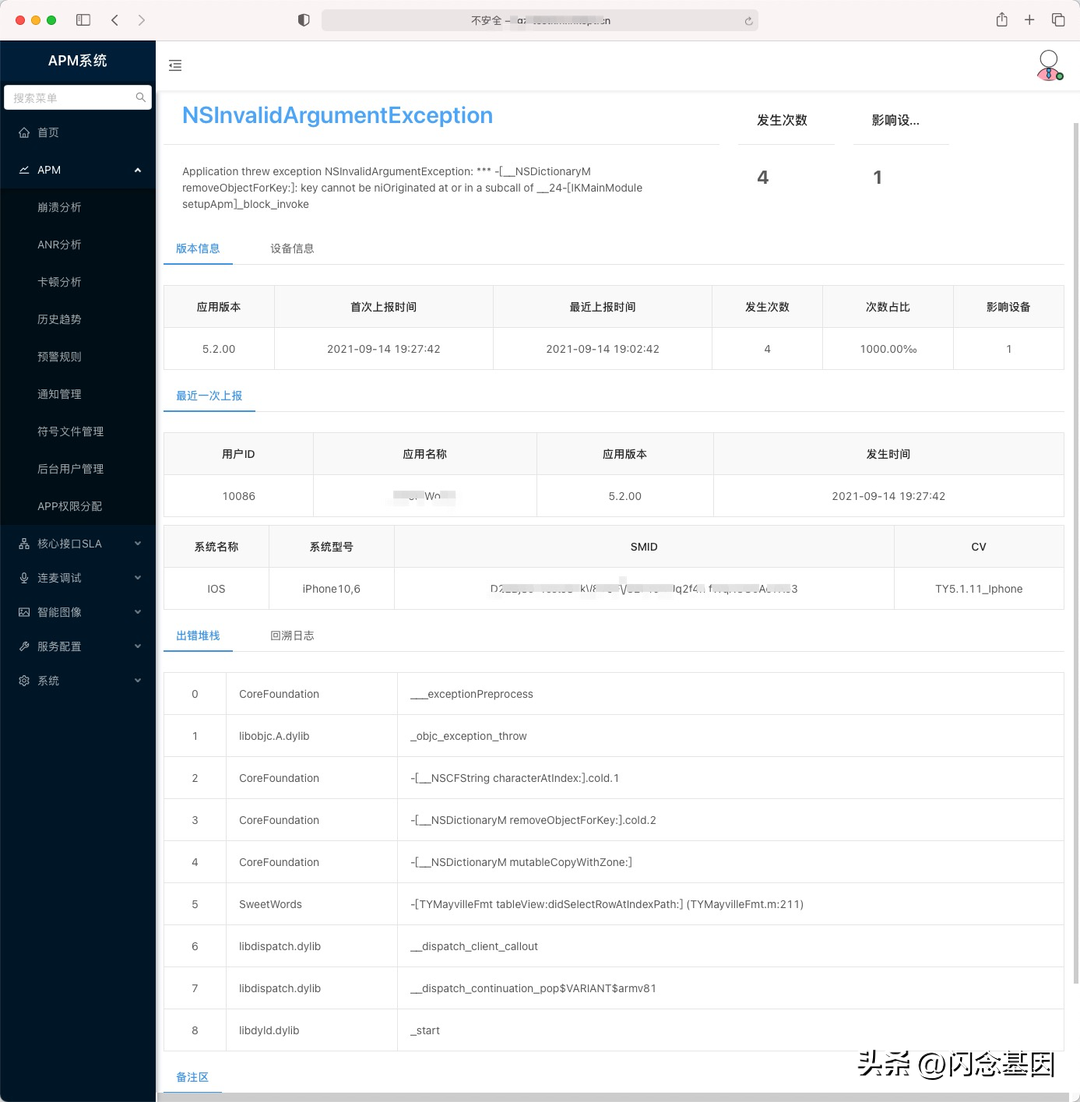
APM的 iOS 端SDK只需要将日志成功上报后,服务端会根据Crash 的信息,如版本号,binaryImage 以及 UUID 等信息进行符号工作,符号化成功后,就可以在管理后台查看到相应的日志。
参考文献
1.Black, David L. The mach Exception Handing Facility.
2.iOS Crash 分析攻略 https://developer.aliyun.com/article/766088
3.《深入解析Mac OSX & iOS操作系统》
作者: 郑更濠、蓝海庭